原文出处
[2111.09734] ClipCap: CLIP Prefix for Image Captioning (arxiv.org)
原文翻译
接上篇
《ClipCap》论文笔记(上)-CSDN博客
4. Results
Datasets.我们使用 COCO-captions [7,22]、nocaps [1] 和 Conceptual Captions [33] 数据集。我们根据Karpathy等人[17]拆分对前者进行分割(对数据集),其中训练集每张图像包含120,000张图像和5个标题。由于 COCO 仅限于 80 个类别,因此 nocaps 数据集旨在衡量对未曾出现的类和概念的泛化。它仅包含验证集和测试集,使用 COCO 本身进行训练。nocaps 数据集分为三个部分——域内仅包含仅描绘 COCO 类的图像,近域包含 COCO 和新类,域外仅包含新类。正如Li等人[19]所建议的,我们只使用验证集来评估模型。尽管一些方法利用新类的对象标签,但我们只考虑没有额外的监督的设置,因为我们发现它在实践中更适用。因此,我们不使用受约束的波束搜索 [2]。概念字幕数据集由 3M 对图像和字幕组成,这些图像和字幕来自网络和后处理。由于图像和字幕的风格种类繁多,它被认为比 COCO 更具挑战性,而不限于特定类别。为了关注概念,该数据集中的特定实体被替换为一般概念。例如,在图 1 中,名称被替换为“政治家”。为了评估,我们使用由 12.5K 图像组成验证集,因为测试集不公开。因此,我们没有使用该集合进行验证。
Baselines.我们将我们的方法与Li等人[19](称为Oscar)、视觉语言预训练模型(VLP)[47]和Anderson等人[4]的杰出工作进行了比较,记为BUTD。这些模型首先使用目标检测网络[31]生成视觉特征。然后BUTD利用LSTM生成字幕,而VLP和Oscar使用transformer,训练方法与Bert相似,VLP 和 Oscar 都在数百万个图像-文本对上利用了广泛的预训练过程。Oscar [19] 还使用与我们的设置相比的额外监督,以每个图像的对象标签形式。
我们的默认配置采用 Transformer 映射网络,无需微调语言模型,表示为 Ours;Transformer。此外,我们还评估了我们利用 MLP 映射网络的变体,并对语言模型进行微调,表示为 Ours;MLP + GPT2 tuning。其他配置在表1(D)中进行了评估。

Evaluation metrics.与Li等人[19]类似,我们使用常用指标BLEU[27]、METEOR[10]、CIDEr[37]和SPICE[3]在COCO数据集上验证我们的结果,以及使用CIDEr和SPICE的nocaps数据集。对于概念字幕,我们报告了作者 [33] 所建议的 ROUGE-L [21]、CIDEr 和 SPICE。此外,我们测量训练时间和可训练参数的数量,以验证我们方法的适用性。减少训练时间可以快速获得新数据的新模型,创建一组模型并降低能耗。与其他工作类似,我们报告了 GPU 小时的训练时间和使用的 GPU 模型。可训练参数的数量是表示模型可行性的一种流行度量。
Quantitative evaluation.具有挑战性的概念字幕数据集的定量结果如表中所示。1(A)。可以看出,我们超越了VLP的结果,同时训练时间减少了几个数量级。我们注意到,我们没有微调 GPT-2 的轻量级模型在该数据集上取得了较差的结果。我们假设由于风格种类繁多,比我们的轻模型需要更多的表达模型,这会导致参数计数显着降低。我们只与VLP进行比较,因为其他基线没有发布结果,也没有针对该数据集训练模型。标签。
1(B) 显示了 nocaps 数据集的结果,其中我们获得了与最先进的 Oscar 方法相当的结果。可以看出,Oscar 获得了稍好的 SPICE 分数,我们获得了略好的 CIDEr 分数。尽管如此,我们的方法只使用了一小部分训练时间和可训练参数,不需要额外的对象标签,因此在实践中更有用。
标签。1(C) 显示了 COCO 数据集的结果。Oscar 取得了最好的结果,但是,它以对象标签的形式使用额外的输入。我们的结果接近于VLP和BUTD,它利用了更多的参数和训练时间。请注意,VLP 和 Oscar 的训练时间不包括预训练步骤。例如,VLP 的预训练需要对消耗 1200 GPU 小时的概念字幕进行训练。
概念字幕和 nocaps 都旨在对比 COCO 更多样化的视觉概念进行建模。因此,我们得出结论,我们的方法更适合使用快速训练过程泛化到不同的数据。这源于利用CLIP和GPT-2已经丰富的语义表示。
Qualitative evaluation.图3和图4分别给出了概念字幕和COCO数据集测试集中未经策划的第一个示例的可视化结果。可以看出,我们生成的标题是有意义的,并且成功地描述了两个数据集的图像。我们在图 1 中展示了从网络中收集的其他示例。可以看出,我们的概念字幕模型可以很好地推广到任意看不见的图像,因为它是在相当大的和多样化的图像集上训练的。我们还在智能手机图像上的图5结果中展示了这一点,以进一步证明对新场景的泛化。此外,即使仅在 COCO 上训练,我们的模型也成功地识别了不常见的对象。例如,我们的方法识别木勺或蜡烛比图 3 中的 Oscar 更好的蛋糕,因为 CLIP 是在一组不同的图像上进行预训练的。然而,我们的方法在某些情况下仍然失败,例如识别图 3 中火车旁边的自行车。这继承自 CLIP 模型,它确实不首先感知自行车。我们得出结论,我们的模型将受益于提高 CLIP 对象检测能力,但将此方向留给未来的工作。对于概念字幕,我们的方法主要产生准确的字幕,例如感知图 4 中的绿色 3d 人。正如预期的那样,我们的方法仍然存在数据偏差。例如,它将图 4 中的卧室图像描述为“该属性在市场上为 1 英镑”,在训练期间目睹了此类属性广告字幕。


Language model fine-tuning.如第 1 节所述。3,微调语言模型会产生更具表现力的模型,但随着可训练参数数量的增加,它也更容易受到过度拟合的影响。从表中可以看出。1,两种变体——有和没有语言模型微调——具有可比性。在极其复杂的概念字幕数据集上,我们通过微调获得了更好的结果。虽然在流行的 COCO 数据集上,避免微调取得了更好的结果。关于 nocaps 数据集,结果大致相等,因此较轻的模型更可取。因此,我们假设呈现独特风格的极其详细的数据集或数据集需要更多的表达能力,因此它更有可能从微调中受益。
Prefix Interpretability.
为了进一步理解我们的方法和结果,我们建议将生成的前缀解释为单词序列。由于前缀和词嵌入共享相同的潜在空间,因此可以类似地对待它们。我们在余弦相似度下将每个 kprefix 嵌入解释为最接近的词汇标记。图 6 显示了图像、生成的字幕及其前缀解释的示例。当映射网络和 GPT-2 都经过训练时,解释是有意义的。在这种情况下,解释包含与图像内容相关联的显着词。例如,摩托车并在第一个示例中展示。然而,当我们只训练映射网络时,解释基本上变得不可读,因为网络还负责操纵固定语言模型(此时mapper纯纯做一个适配器的作用)。事实上,同一模型的不同图像之间共享相当大的前缀嵌入部分,因为它对 GPT-2 执行相同的调整。

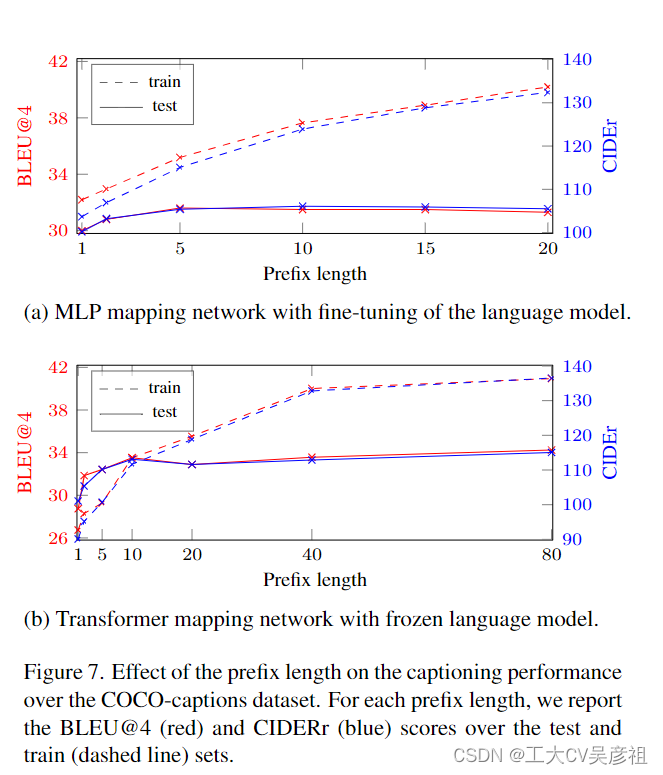
Prefix length.Li 和 Liang [20] 表明,增加前缀长度的大小,直到某个值,可以提高模型在底层任务上的性能。此外,任务之间的饱和度长度可能不同。对于图像字幕任务,我们在我们方法的两种配置上使用 COCO 数据集对前缀长度进行了消融研究:Ours;Transformer 和 Ours;MLP + GPT2 调整。结果如图7所示。对于每个前缀大小和配置,我们训练网络5个epoch,并报告测试集和训练集上的BLEU@4和CIDEr评分。
如图 7a 所示,由于可训练参数的数量很大,在允许调整语言模型的同时增加前缀大小会导致对训练集的过度拟合。然而,当语言模型被冻结时,我们对训练和测试的评估都有改进,如图 7b 所示。当然,非常小的前缀长度会产生较差的结果,因为模型不够表达。此外,我们指出 MLP 架构本质上更有限,因为它不适用于长前缀。例如,前缀大小为 40 意味着具有超过 450M 参数的网络,这对于我们的单个 GPU 设置是不可行的。Transformer 架构允许增加前缀大小,而参数数量仅略有增加,但仅增加到 80——由于注意力机制的二次内存成本。
Mapping network.映射网络架构的消融研究如表中所示。1(C),(D)。可以看出,通过语言模型微调,MLP 取得了更好的结果。但是,当语言模型被冻结时,Transformer会更好。我们得出结论,当使用语言模型的微调时,变压器架构的表达能力是不必要的。
Implementation details.对于 MLP 映射网络,我们使用 K = 10 的前缀长度,其中 MLP 包含单个隐藏层。对于转换器映射网络,我们将 CLIP 嵌入设置为 K = 10 个常量标记,并使用 8 个多头自注意力层,每个隐藏层有 8 个头。我们使用 40 的批量大小训练了 10 个 epoch。为了优化,我们使用 Loshchilov 等人介绍的权重衰减修复的 AdamW [18]。 [24],学习率为 2e-5 和 5000 个预热步骤。对于 GPT-2,我们采用了 Wolf 等人的实现。 [41]。
5. Conclusion
总体而言,我们基于 CLIP 的图像字幕方法易于使用,不需要任何额外的注释,并且训练速度更快。尽管我们提出了一个更简单的模型,但随着数据集变得更加丰富和更多样化它展示了更多优点。我们将我们的方法视为新的图像字幕范式的一部分,专注于利用现有模型,同时只训练最小映射网络。这种方法本质上学会了将预训练模型的现有语义理解适应目标数据集的风格,而不是学习新的语义实体。我们相信,在不久的将来利用这些强大的预训练模型将获得牵引力。因此,了解如何利用这些组件是非常有意义的。在未来的工作中,我们计划通过利用映射网络将预训练模型(例如 CLIP)合并到其他具有挑战性的任务中,例如视觉问答或图像到 3D 翻译。

![[数据集][目标检测]刀具匕首持刀检测数据集VOC+YOLO格式8810张1类别](https://i-blog.csdnimg.cn/direct/affb62e1d9f84d059068e0ff6c4d5fd7.png)